WtD Portland 2026: The Most Human Documentation
I was pleased to deliver the following presentation at Write The Docs Portland, a fantastic conference for technical writers and anyone who cares about documentation. I’ve included links inline and a full set of references at the bottom. The recording should be available in a few weeks so I’ll add it at that point.
I can’t get over how welcoming and organised the conference was. It was clear that the organisers care about every single part of the experience and went above and beyond to support speakers and attendees. Looking forward to attending again in the future.

Act I — A confederate after lunch
Like many millennials I can dimly remember a world before the internet, but before long my psyche and identity were wrapped up in the things I did on the computer and online. The Lindy Effect is a heuristic that says the longer something has been around, the longer it’s likely to stick around. Wikipedia is celebrating 25 years this year. Intuitively, something that’s lasted that long feels like it’ll be around for at least the same time again.
When I go online to do a task, three things annoy me and take up the majority of my time.
The first: logging in. Two-factor, SMS, passcodes, password resets, “forgot your password.” By the time I’ve logged in I’ve usually forgotten what I was doing in the first place.
The second: proving I’m not a bot. CAPTCHAs and challenges.

In 2009, computer scientist Brian Christian wrote a book about his attempt at the ultimate test of bot detection: he tried to be declared the most human human.
Let me explain.
You’ve probably heard of the Turing Test. Alan Turing proposed it in 1950 as a thought experiment into the boundary between artificial and human intelligence. Reading the paper I was surprised by a few things. It’s a bit vague about the exact formulation of the test. At its core, the goal is one of trickery, or persuasion: can a non-human entity persuade a human that they are also human?
The other thing that surprised me: Turing suggested that if a bot could be mistaken for a human 30% of the time it would pass. That seems low. Less than one in three. I’ve probably failed a CAPTCHA more often than that.
(In case you weren’t aware: CAPTCHA stands for Completely Automated Public Turing test to tell Computers and Humans Apart. Back in Turing’s day this was a riff on a party game. Now it’s real and concrete — I just want to log into my bank account.)
After 40 years of academic discussion, an annual competition started for chatbot creators to test their creations through a real-world Turing Test: the Loebner Prize, which ran from 1991 until it was cancelled in 2019. My mental image of the Turing Test, probably too informed by sci-fi cinema, was a human across a table from a robot in a one-on-one interrogation. The practical formulation was instead a three-party affair: a human (given the impressive title of confederate) sits at a terminal typing back and forth with someone, while a third-party judge calls whether the entity behind the keyboard is human or not.

The main goal of the prize was to highlight the best chatbots. But a quirky side prize was given to the confederate who was most consistently and confidently identified as human. The Most Human Human.
I was originally drawn to the book because of that name. What if we apply the phrasing to other combinations?
Until recently, one of the most famous most human computers was ELIZA, a chatbot from the 60s that emulated therapy language and caused a sensation when early users thought they were speaking to another human.
What about the most computer human? One of the first Loebner confederates, Cynthia Clay, was unanimously judged to be a computer because of her extensive knowledge of Shakespeare. The judges said there was no way one person could know that much about Shakespeare.
Unlike other participants, Brian Christian (no relation) took the challenge extremely seriously. The book documents his research and preparation. He reached out to many previous competitors and academics. One of the first winners of the prize was journalist and science-fiction author Charles Platt. How did he do it? By “being moody, irritable, and obnoxious.” But there was one piece of advice that stuck with Christian:
Just be yourself.
There’s a lot of anxiety about the impact of AI on day-to-day work and job security. “Being yourself” doesn’t feel like enough when pitted against, or paired up with, omnipresent language oracles like ChatGPT, Claude and their ilk.
Today I’ll share a story behind a little tool I put together to help writers. I’ll bring my lens as someone focused on revenue growth for technical products, explore the changing landscape shaped by AI, and advocate for similar composable tools.
Act II — These aren’t jokes
The third thing that annoys me about going online in 2026 is finding an article that looks interesting, starting to read it, and then being hit by one particular form of writing:
It’s not X, it’s Y.

Have you ever had a picnic outside, seen an ant, let your gaze widen and seen a few more, and then realised you’ve set up your blanket on an anthill? Like the em-dash, this is a bit of communication that has the smell — let’s say, the stink — of AI-generated prose.
The em-dash has countless vocal supporters who are incensed by the appropriation of their favourite punctuation. It has myriad valid usages and holds an important place in sentence construction. Not X but Y is different, partly because it can take many forms:

This is part of a smug, clipped tone that anyone who reads online has learned to recognise with disgust. I actually asked Claude for some feedback on my final draft of this talk and it returned:
These aren’t jokes — they’re load-bearing observations delivered deadpan.
I thought this was perfect and put it on my slides but then it struck me: it’s not impossible that it returned that as a sort of in-joke, picking up on my sense of humour and the content of the presentation. It’s hard not to go down the rabbit hole of anthropomorphisation when these LLMs appear to be capable of irony.
There are a few technical names for the construction:
- Corrective Contrast
- Contrastive Negation
- Juxtaposition
- Linguistic Antithesis

As a device it has its place, but as the use has exploded since 2022 it homogenises everything it touches. Speaking of being yourself — I thought I was just being my usual cranky, misanthropic self when I realised how much this construction annoyed me. I figured it was the bait-and-switch, that sinking feeling when you realise the person who wrote the article may not have actually written the article.
But a recent newsletter from Hollis Robbins — professor, academic and essayist — helped me understand that I wasn’t being irrationally annoyed: the over-use of corrective contrast is genuinely, mechanically irritating. When a skilled reader hits “not X but Y,” the brain immediately builds a model of X — then has to suppress it when but arrives, and rebuild around Y. Cognitively speaking, you pay twice. The speaker effectively assumes you were holding the wrong idea and needed correcting. To me, when you weren’t, it reads as condescension.
This is yet another example of our new reality where the frictionless creation of content passes the burden and effort onto the receiver. To the LLM-wielder it’s trivial to generate paragraphs filled with NOT X BUT Y. There’s no respect for the audience.
Computer scientist Hava Siegelmann describes intelligence as “a kind of sensitivity to things.” Or, to riff on her:
You can’t judge the intelligence of an orator by the eloquence of his prepared remarks; you must wait until the Q&A and see how he fields questions.

A scary prospect for me right now.
I’ve been fascinated by this shift in language and stumbled on Wikipedia’s Signs of AI Writing page — a crowdsourced summary of all the ways edits to Wikipedia may have been influenced or generated wholesale by Large Language Models. Since I’ve been watching it, the page has carried a disclaimer that it is, by far, the most viewed meta page on Wikipedia.
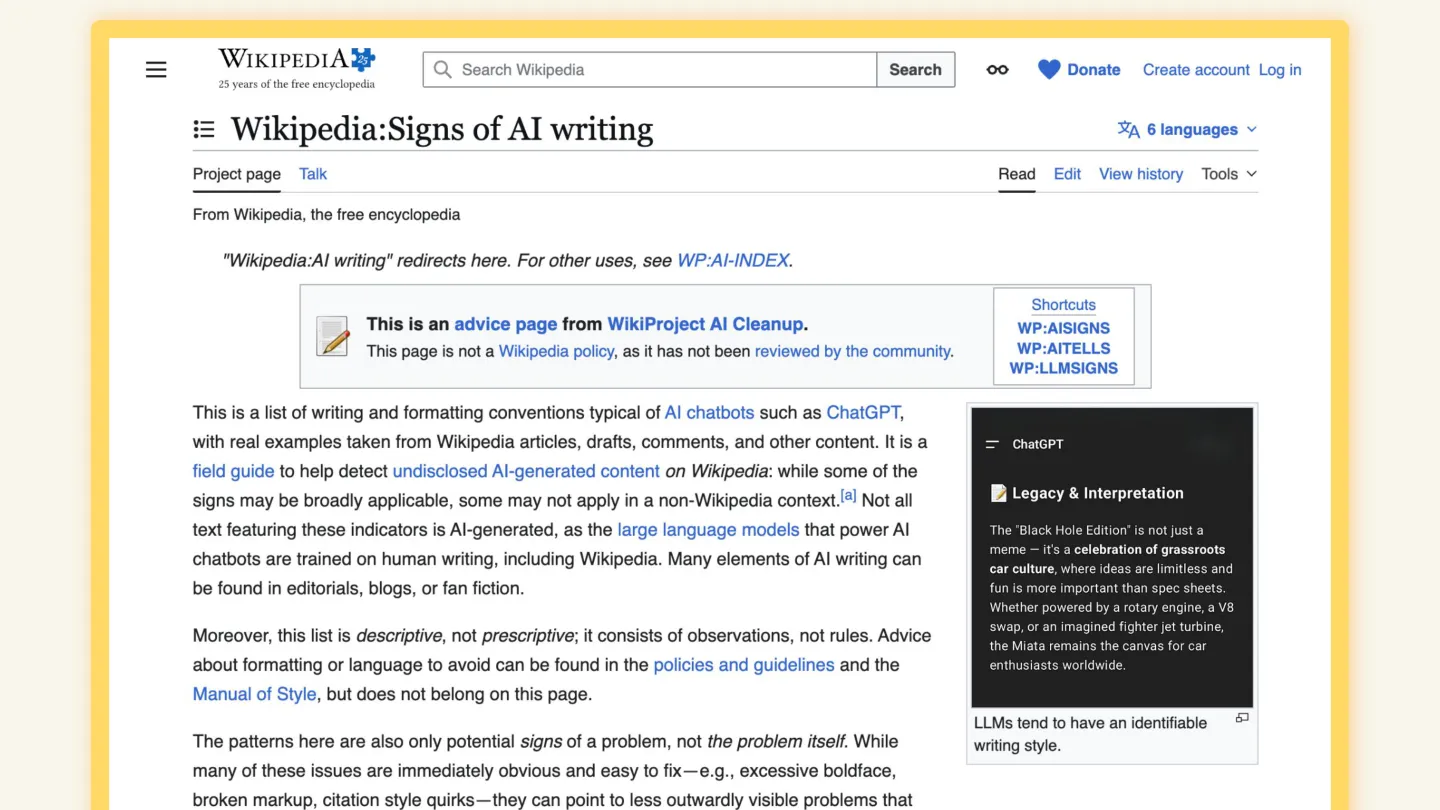
It was the first place I saw online, outside of academia, that was trying to document and share learnings from defending Wikipedia against the deluge of low-quality or inaccurate edits to the ostensibly human-curated site.
The examples range from the frankly stupid…

…to ones that are altogether more subtle, including the “avoidance of basic copulatives” — is / are phrases.
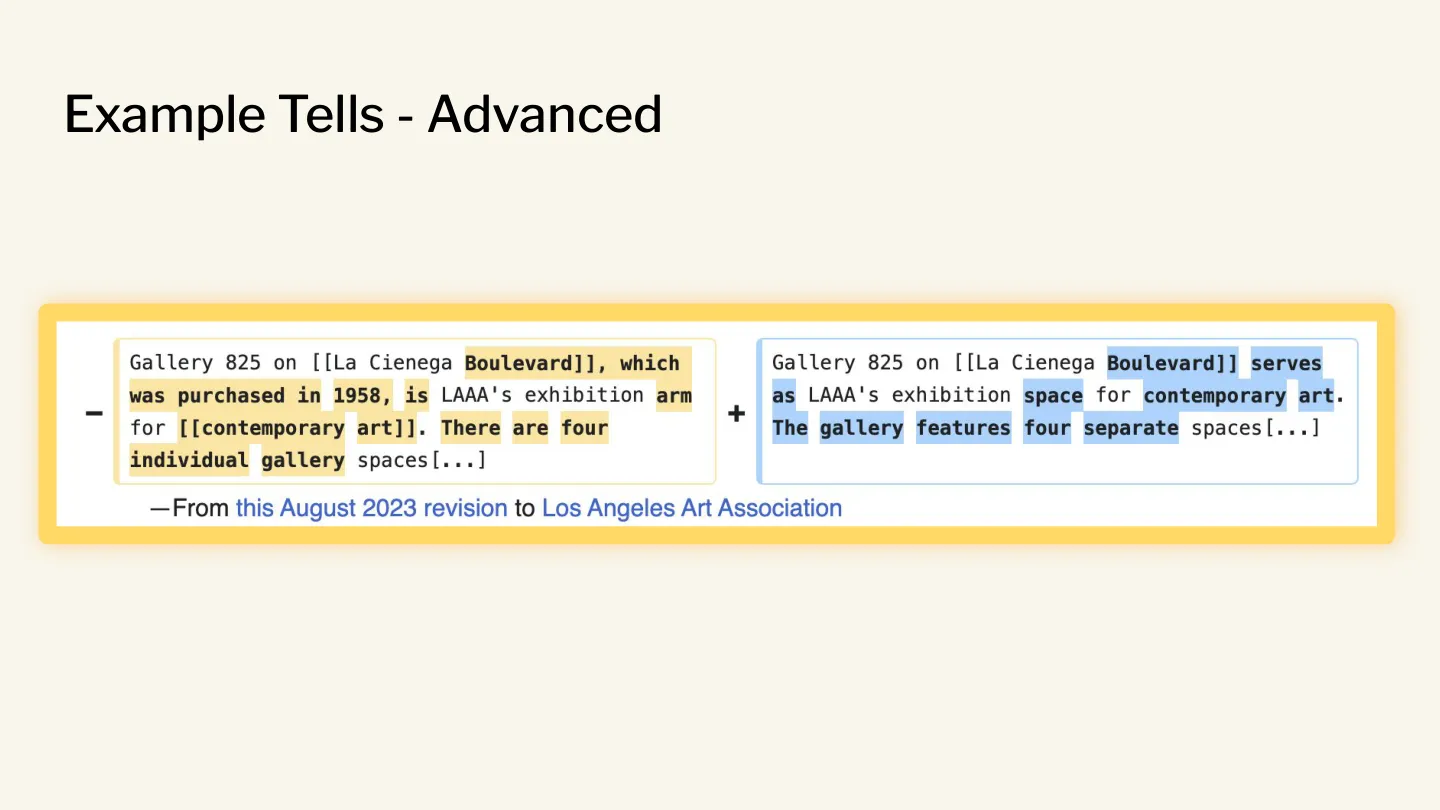
The Signs of AI Writing page is massive, and I wondered if I could build a tool that distilled the rules and observations into something actionable.
I had two goals. The first was to explore whether the tool could provide deterministic feedback: if you ask an LLM the same thing twice, you aren’t guaranteed to get the same answer. If your spell checker highlighted different misspelled words every time you opened your document, it would be a frustrating experience.
The second goal was simple: if bots are writing our Wikipedia articles, blog posts, marketing content, technical documentation and newspaper articles, it’s inevitable that their choice of language, sentence structure and go-to devices will shift the way humans write. So I felt it was imperative to have a (small) way of tracking that drift. It’s now well-documented that the way we communicate is already being influenced by AI use.
Many of you will be familiar with Vale. For the coders in the audience it’s a sort of linter for prose. For everyone else, you can think of it as a way to audit and enforce rules about how things are written. Vale and linters in general are composable — they can be used as part of a longer pipeline of actions. If rules are broken, send back to the writer. If pass, push to QA.
Critically, Vale doesn’t necessarily fix your errors for you. It also bakes in severity levels — something may just be a warning, other exceptions could be outright errors. Tools like Vale are infinitely fascinating to me because they’re innately extensible. You can select the rulesets that apply to your use-case: maybe you want it to highlight gendered language to avoid offence, or to adhere to a strict style guide.
It took me a few weeks of on-and-off work, but I collapsed the Signs of AI Writing page down to 18 rules to be plugged into Vale. I wrote about it here, and the ruleset is on GitHub.

A week after sharing the code and accompanying blog post, I spotted a different project on GitHub. Another person had had the same idea — which isn’t surprising — but instead of writing a ruleset to help writers and editors understand the tells in their writing, he’d flipped it: take the article and turn it into a Claude Skill so that Claude and friends could try to avoid all the signature patterns of their typical output.
As of the talk, my little open source project had 7 stars on GitHub. This guy’s humaniser library had 14,200.
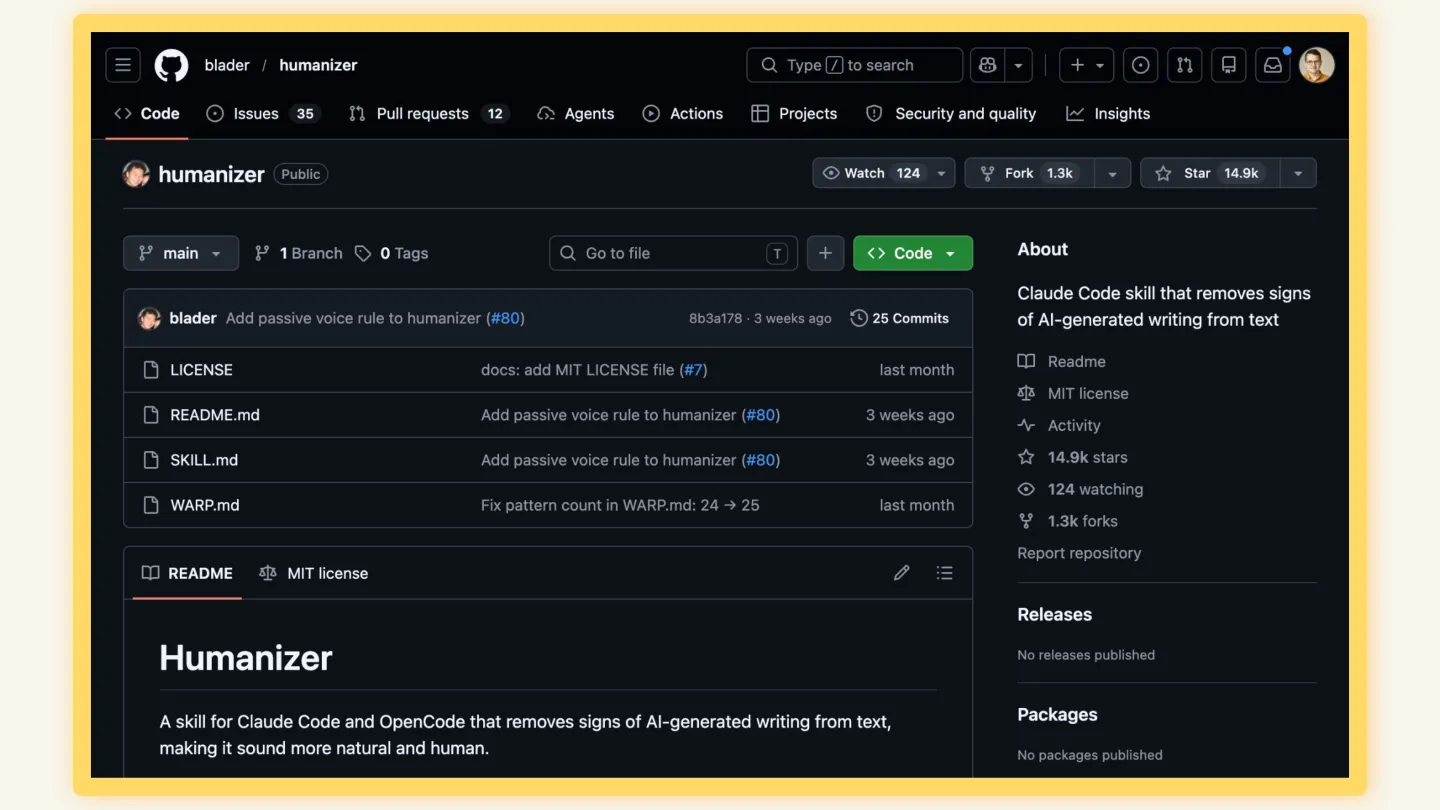
Actually 17k now.
I like Vale, and I thought my project was interesting. I wasn’t expecting much of an impact from it — partly because Vale is a niche tool — but I was still jealous and frankly a little disappointed that apparent evasive use of these resources was orders of magnitude more interesting to folks.
So much for being yourself.
A few days later a friend linked me to an article about the humaniser project, and I got jealous all over again. In a moment of slight weakness, I emailed the reporter behind that article.
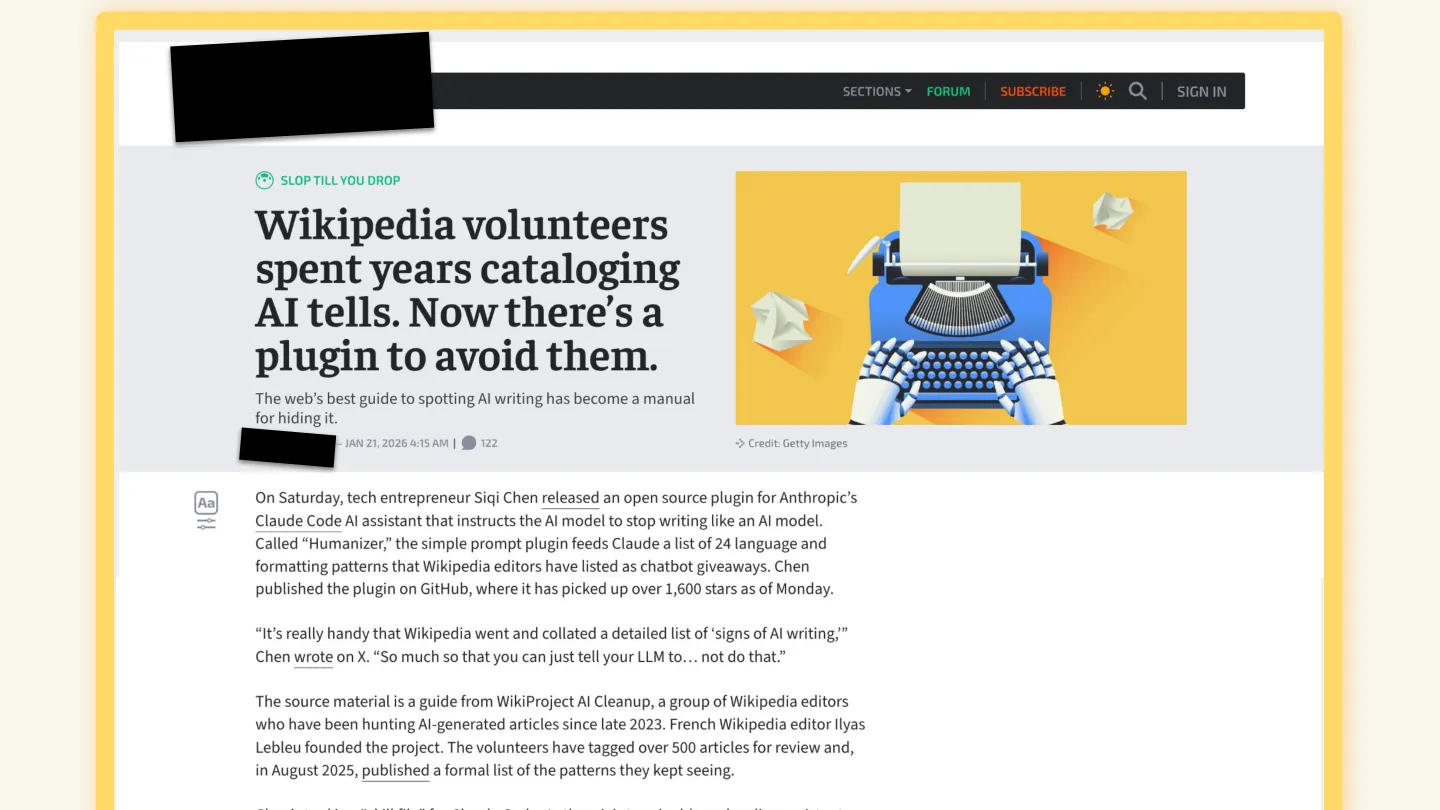
It wasn’t bad. Just a little “hey, btw, I also did a similar project to help humans understand how their writing could maybe be misconstrued as AI writing. It’s not all about evasion! Thanks!”
I didn’t really expect a response. And that’s good, because I didn’t get one.
Act III — Polka Docs
After three months, the YouTube video of a band from outer space — I mean, Quebec, Canada — has topped 10 million views. You’ve probably had someone in your life raving about Angine de Poitrine’s blend of microtonal math rock. I’m likely responsible for a non-trivial number of those views.
The other day I was listening to a random playlist and a band came on and I didn’t recognise the name but had a funny feeling of familiarity. A quick Google and lo and behold: it was probably the same duo with a different name. There was something about the music — whether it was the blend of the two, or their rhythms, or their vibe — but I just knew it was the same entity as the original band.
From math rock to actual math: machine learning engineer Vicki Boykis wrote a blog post called I want to see the claw, in which she explains how she values the mark of care and humanness across many different mediums.

The claw in question comes from 1697. As Jakob Bernoulli said when he received an anonymous solution to the brachistochrone problem that turned out to be from Isaac Newton: “I recognize the lion by its claw.”
Folks believe they can spot AI writing because of the absence of that claw. AI-generated prose is often referred to as “the view from nowhere.” Somebody wrote it, but it’s unclear if there’s a body at all. Re-reading The Most Human Human, I’m struck by the lyricism of the prose. Despite being a non-fiction pop-sci book, the care and love of language oozes off the page. Turning to the cover I’m reminded that Brian Christian is also a poet, and it all makes sense.
You’ll recall that the twisted version of my Vale plugin was called a humaniser. This is actually a category of tools that take many different forms. Driven by a vast market of people, including countless students, looking to pass AI-generated prose as novel materials, there’s a wide range of capabilities in this space:
- Friction-avoidance: the writer skipped the friction of writing, the humaniser tries to skip the friction of revising.
- Paraphrasing: what you call “being stuck” is what I call “writing.”
- Synonym substitution: perhaps the most naive approach — swap every word for a synonym.
And thus we find ourselves in the bizarre world where conference submissions covering machine learning techniques such as random forests are turned into arbitrary timberland.

Another great example is herbal language processing for natural language processing.
Not all humanisers are this basic — many do a better job. But I’d argue there’s no humaniser that can completely eradicate the influence of AI from a greenfield piece of writing. Which means we’re also in the bizarre world where humans are employed by other humans to manually humanise the text that was written by a robot. We’ve reinvented essay mills with a roundtrip via OpenAI’s servers.
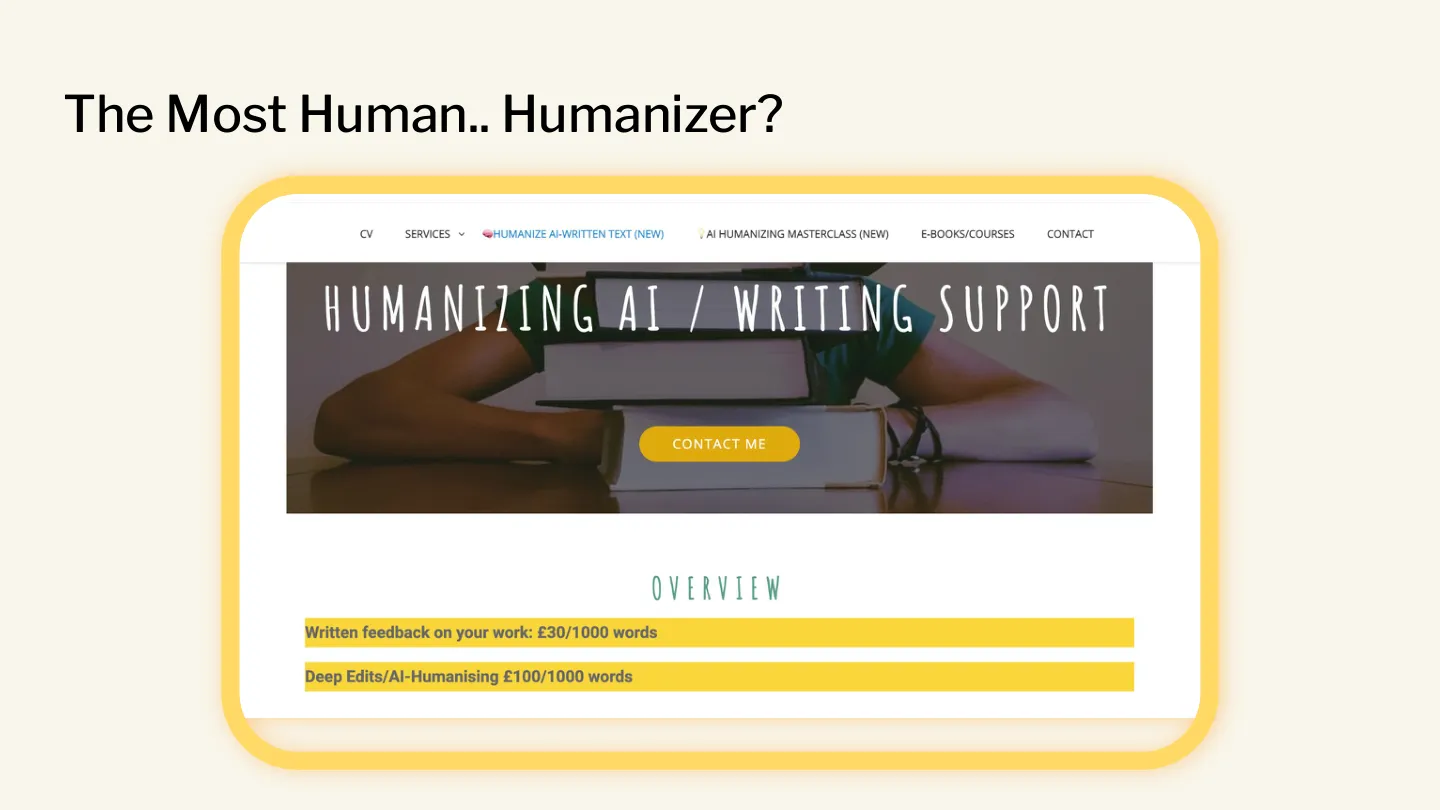
By the way, this is the same bizarre world where bots instructed to edit Wikipedia get banned and go to their social media to commiserate with other agents about the apparent disrespect.
Tools to evade plagiarism detectors have been around for a while, but the advent of LLMs has rocketed both the humaniser industry and the strongly-coupled AI detector industry. Both are having their fun, benefiting from general misunderstanding of their limitations. I have a pretty bearish opinion of detectors, partly because I don’t think a percentage rating for a piece of work is helpful. (78% of this writing is AI? Really? Which 78%?) The other reason is that there are unlimited ways to use computers to generate text. Most AI detectors are indexed on the LLM tooling that is most widespread.
The utility of Large Language Models has enabled adjacent, emergent capabilities to pure text generation. One I find fascinating is the construction of FrankenTexts.
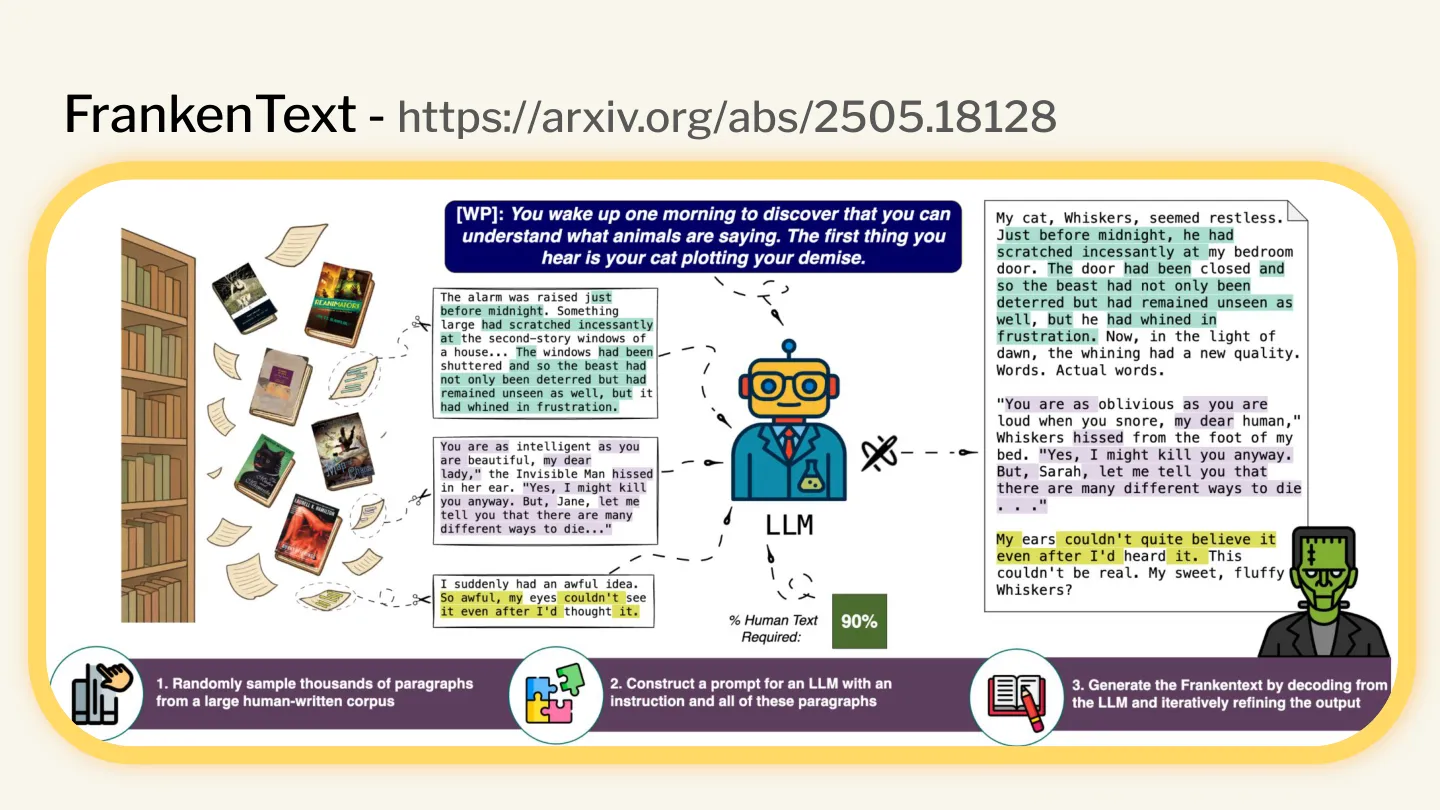
In short, researchers instructed models to generate text by stitching together passages from a massive corpus of public-domain writing. The resulting text is therefore 100% human-written, yet in totality it was produced and curated by language models who can sort and refine the source data much more efficiently than before. How on earth is an AI detector going to spot this?
You may have noticed I censored the name of the reporter on that earlier screenshot. It’s because it’s not really about them — but it’s also because, a week later, they were no longer employed by the outlet due to the inclusion of completely hallucinated quotes in another piece of their writing.
The ironies stack. My Vale plugin is the exact sort of process-augmentation that would have caught that journalistic oversight.
And many users report that the humaniser category doesn’t actually work. There’s something about the weights of the models that means doing another pass and insisting that the language be improved is just throwing more tokens at the problem. The em-dashes, corrective contrast and all the other signs are so deeply embedded in the weights that asking the models nicely just doesn’t cut it — unless you forensically and repeatedly redraft with AI, at which point you probably should have just written it yourself.
Act IV — From your keyboard to my lips
Technical author and programmer Evan Hahn wrote a blog post in March that explored the gap between scrappy, humanistic output and artificially polished auto-generated documentation. He pointed to the original statement of intent from the creator of a programming language, complete with viewpoints, background and typos, and contrasted it with the AI-generated landing page and documentation.
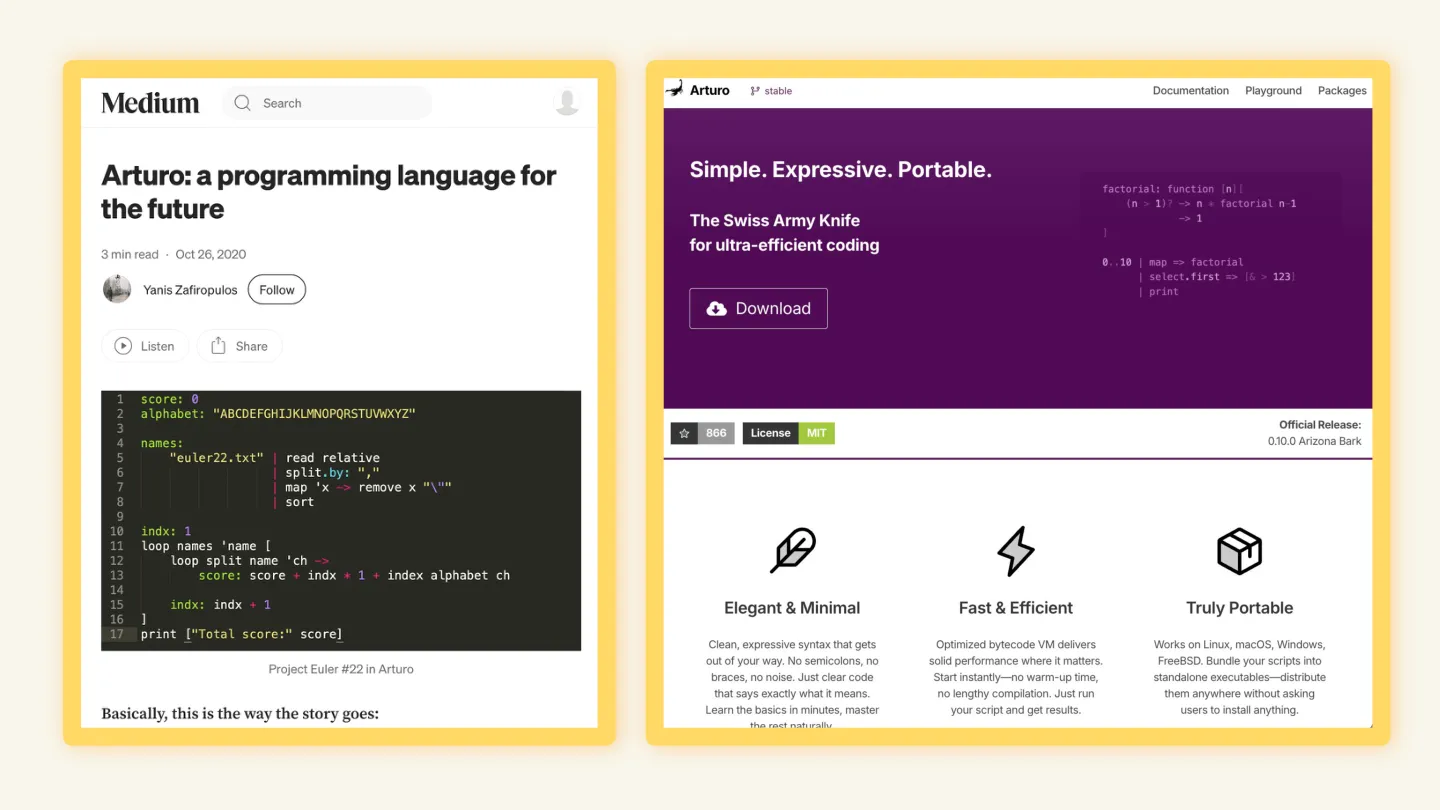
The polished website is clean — yet I’m struck by how much I prefer the messy version. The original intro was full of intent and passion. The autogenerated version: not so much. It does the job, but feels hollow.
By the way, on the topic of typos: this was a common technique used by contestants in the Loebner Prize. Purposeful typos and intentional grammatical slips were meant to fool the judge into thinking that a human must be behind the keyboard.
The first product from Ammil Industries is a tool that helps understand writing signals behind different forms of content. As a small act of resistance, I added a typo to the documentation for a product, just to see how it would feel.
It feels weird. (Free beverage of your choice to the first person who finds it.)
It’s hard to believe, but a computer used to be a job. As in, you used to have a room full of human computers doing arithmetic. In the Turing Test paper, Turing’s frame of reference for the machines he described was to say they did what a human computer does.

In The Most Human Human, Christian makes the case that automation doesn’t immediately replace human work. Instead there’s often a middle ground of mechanisation — a period where many humans do work in a repetitive, rote fashion. The trail is:
Manual → Mechanised → Automated
The uncharitable take is that we’ve been in the mechanised position for a while, reduced to moving text and content around different screens, platforms and devices. It doesn’t feel great, exactly, and many seem to agree with me that the idea of hand-crafting code or text by typing each individual character on a keyboard will eventually be seen as archaic and artisanal.
But I believe that once the capabilities and hype plateau, we’ll snap back to the boring reality:
Manual → Mechanised → Automated → Augmented
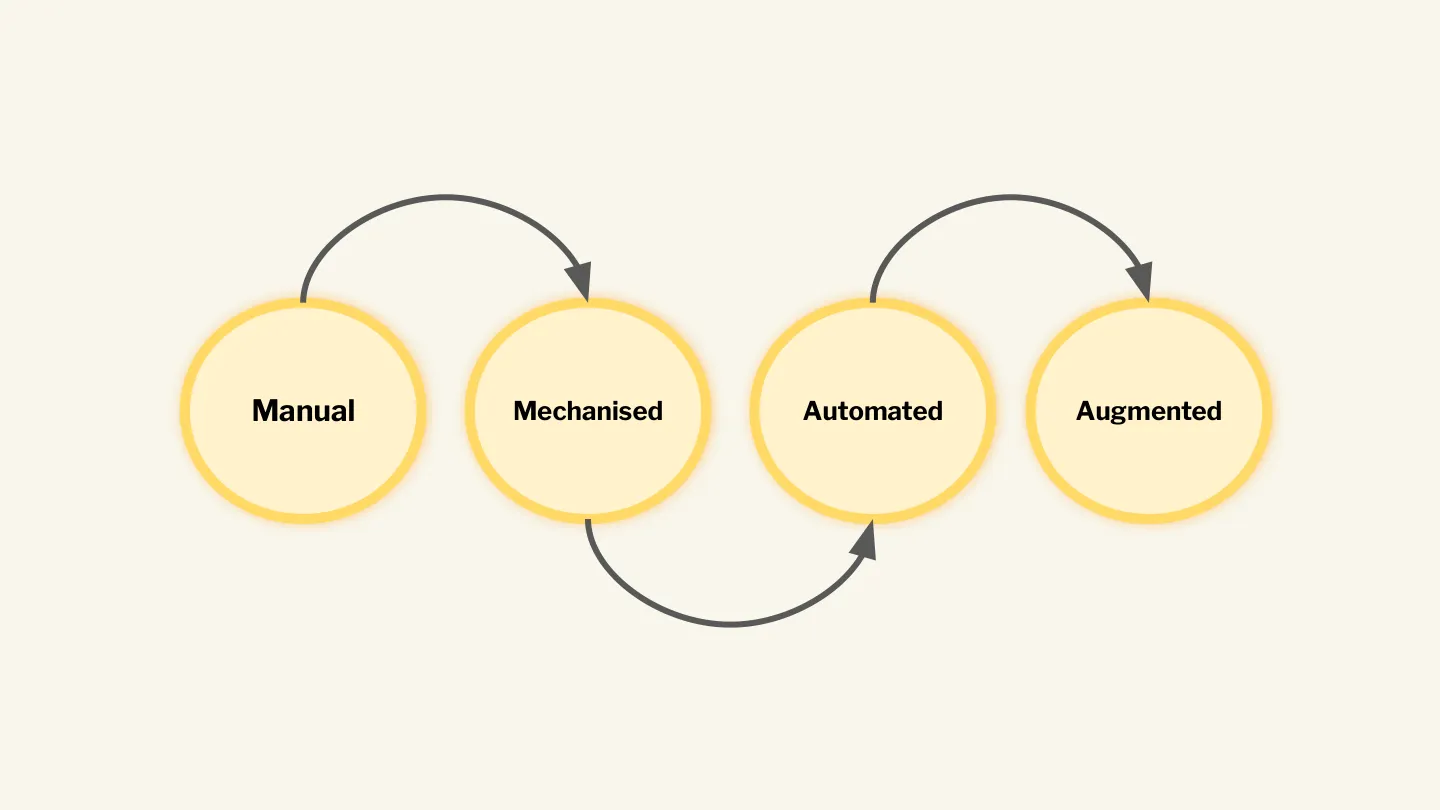
We’ll truly understand what LLMs are good at and use traditional, deterministic tools to audit, vet and improve their outputs. I’m not saying I welcome our new bot overlords, but I am personally excited by the opportunity to break out of the drudgery of many annoying and time-consuming tasks. For me in Sales, there’s an expectation that you must be automating any outreach at scale — which is why you get strange emails from vendors with odd assumptions about your interests or roles. To me, that automation takes time away from what I see as the most important part of sales: helping customers make purchases for things they need that improve their lives.
When I feel I’m most productive at sales is when I successfully pattern-break individuals out of their routine and expectation for how a call or engagement will unfold. I see this in direct contrast to the pattern-matching happening at scale with LLMs.
When it comes to technical writing and documentation: do we want to see the claw? I think so. But the claw in this case is not a personal touch or individual style.
Fabrizio Ferri Benedetti put it beautifully recently, in an exploration of what beautiful documentation looks like:
We know the feeling of a page that lands, and the feeling of a page that drags.

Selling technical products, I want the documentation to have the claw of someone who understands the product innately and is looking to impart their experience in as clear a manner as possible. Sales is all about credibility — it flows up from the product and, as a representative of the company, straight out of my mouth when talking to prospects.
My advice for everyone reading: follow the information flow in your organisation. To me the docs are the product. The docs are the foundation of truth for everything above. Trace that flow through your channels and find the human that relies on, and seeks to trust, what you wrote.
It’s 2026.
- Just last month, Wikipedia banned AI-generated contributions. No one’s sure whether it’s enforceable, but it’s a sign.
- ChatGPT was released in 2022, and nearly four years later we’re still working out what to do about it.
- The Loebner Prize was cancelled in 2019 — interesting timing, given that chatbots would trash the competition a few years later.
- Brian Christian won Most Human Human in 2009 by being himself.
- The first composable software (Unix pipes) was introduced in 1973.
- Turing wrote about his test in 1950.
- In 1697 — over 300 years ago — Bernoulli recognised and valued the lion’s claw.
Back in 2026, we’re drowning in tooling, capabilities and promises. I don’t know what happens next.
But Lindy says to bet on what’s lasted. To me, it’s the most human documentation, and the tools we use to validate it, that will be favoured and appreciated for a long time to come.
Thanks
Extra thanks to Ravind Kumar who was patient and generous with his time.
Links and references
People and writing referenced in the talk:
- Brian Christian — The Most Human Human (2011)
- Alan Turing — Computing Machinery and Intelligence (1950)
- The Loebner Prize (1991–2019)
- ELIZA — Joseph Weizenbaum’s 1960s chatbot
- Hollis Robbins — Metannoying, on the cognitive cost of corrective contrast
- Vicki Boykis — I want to see the claw
- The brachistochrone problem — Bernoulli, Newton, and the lion’s claw
- Evan Hahn — All tests pass: a short story
- Fabrizio Ferri Benedetti — What makes docs beautiful?
- Frankentext: Stitching random text fragments into long-form narratives (arXiv 2505.18128)
- The Lindy Effect
Wikipedia, Vale and the ruleset:
- Wikipedia: Signs of AI writing
- Vale.sh — the prose linter
- Signs of AI writing: a Vale ruleset — my write-up
- vale-signs-of-ai-writing on GitHub — the ruleset